Cloudera Hadoop 集群安装(ubuntu + CDH5.10)
前言
CDH是Cloudera公司的Hadoop发行版,基于稳定版本的Apache Hadoop构建,包含Hadoop,Spark,Hive,Hbase和一些工具等,并集成了很多补丁,可直接用于生产环境。通过Cloudera Manager可以简化hadoop各组件的部署和配置过程。
目前CDH对ubuntu支持的最高版本为14.04,因此不建议使用更高版本的ubuntu来部署CDH。
环境准备:
1.配置网络(所有节点)
修改hostname:
$ sudo vi /etc/hostname
cdh01
修改IP地址:
$ sudo vi /etc/network/interfaces
auto eth0
iface eth0 inet static
address 172.16.13.11
netmask 255.255.255.0
gateway 172.16.13.254
重启网络服务生效:
$ sudo ifdown eth0 && sudo ifup eth0
修改ip与主机名的对应关系:
$ sudo vi /etc/hosts
172.16.13.11 cdh01
172.16.13.12 cdh02
172.16.13.13 cdh03
2.配置SSH(所有节点)
启用root登陆(CDH5.10需要进行此步操作)
$ sudo vi /etc/ssh/sshd_config
#PermitRootLogin without-password
PermitRootLogin yes$ sudo service ssh restart
$ sudo passwd root
设置ssh无密码登陆
//在主节点上执行一路回车,生成无密码的密钥对
$ ssh-keygen -t rsa
//将生成的密钥文件复制到其它节点
$ ssh-copy-id cdh02
$ ssh-copy-id cdh03
测试:在主节点上ssh hadoop2,正常情况下,不需要密码就能直接登陆进去了。
3.安装Oracle JDK(所有节点)
运行CDH5必须使用Oracle的Jdk,需要Java 7及以上版本支持。
在Oracle的官网下载jdk包,解压到相应目录,例如/usr/java/jdk1.8.0_121:
$ sudo tar -zxvf /home/user/jdk.xx.tar.gz -C /usr/java/
配置环境变量,配置一个全局的JAVA_HOME变量:
$ sudo vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_121
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=.:${JAVA_HOME}/bin:$PATH$ source /etc/profile
4.安装配置MySql(主节点)
安装mysql服务器:
$ sudo apt-get install mysql-server
根据提示设置root的初始密码:
$ sudo mysqladmin -u root password 'szgwnet'
启动mysql服务:
$ sudo service mysql start
创建mysql数据库:
$ mysql -uroot -pxxxxxx
#hive
create database hive DEFAULT CHARSET utf8 COLLATE utf8_general_ci;#Hue
create database hue DEFAULT CHARSET utf8 COLLATE utf8_general_ci;#Oozie Server
create database oozie DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
设置root授权访问以上所有的数据库:
//授权root用户在主节点拥有所有数据库的访问权限
grant all privileges on *.* to 'root'@'cdh01' identified by 'password' with grant option;
flush privileges;
配置 mysql connector 驱动
MySQL Connector官方JDBC驱动地址:
https://dev.mysql.com/downloads/connector/j/
$ cd /usr/share/java
$ sudo ln -s mysql-connector-java-5.1.41.jar mysql-connector-java.jar
//也可以将jar包重命名为 “mysql-connector-java.jar”,多个版本时建议用软链。

5.配置NTP服务(所有节点)
集群中所有主机必须保持时间同步,如果时间相差较大会引起各种问题。这里以namenode节点作为ntp服务器与外界对时中心同步时间,随后对其它所有节点提供时间同步服务。Cloudera建议所有CDH节点都需要启动ntpd服务,要不然会报“时钟偏差”的错误。
安装NTP组件
$ sudo apt-get install ntp
配置NTP服务(管理节点)
在配置之前,先使用ntpdate手动同步一下时间,避免本机时间与标准时间差距太大:
//跟内网时间服务器或Internet时间
$ sudo ntpdate -u 172.16.10.1
or
$ sudo ntpdate -u time.nist.gov
NTP主要的配置文件为:/etc/ntp.conf,
$ sudo vi /etc/ntp.conf
# 设置用于校时的上层时间服务器
server 172.16.10.1 prefer
server time.nist.gov# 外部时间服务器不可用时,以本地时间作为时间服务
server 127.127.1.0
fudge 127.127.1.0 stratum 10
restrict 192.168.13.0 mask 255.255.255.0 nomodify
broadcast 172.16.13.255
重启NTP时间服务:
$ sudo service ntpd restart
配置ntp客户端
NTP客户端配置主要将ntp server指向管理节点:
//设置cdh01 为ntp server
$ sudo vi /etc/ntp.conf
server cdh01 prefer//先手动同步一下时间,一般需要等待5-10分钟才可以正常同步。
$ sudo ntpdate -u cdh1
重启NTP服务自动同步时间:
$ sudo ervice ntpd restart
$ sudo cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
6.配置本地硬盘(datanode)
Datanode节点一般会配置多块本地硬盘(非RAID方式),这里需要提前对每块硬盘进行格式化和挂载。
格式化所有本地数据盘:
//此处为实验环境新建一个lv卷模拟一块硬盘
$ sudo lvcreate -L 20G -n disk1 ubt1404-vg//格式化为ext4
$ sudo mkfs.ext4 /dev/mapper/ubt1404--vg-disk1
将所有磁盘挂载到指定目录:
//尝试手工挂载是否正常
sudo mount /dev/mapper/ubt1404--vg-disk1 /ldisk/disk1//编辑fstable,将所有数据盘分别挂载到ldisk目录下diskx
$ sudo vi /etc/fstable
/dev/mapper/ubt1404--vg-disk1 /ldisk/disk1 ext4 rw 0 0
/dev/mapper/ubt1404--vg-disk2 /ldisk/disk2 ext4 rw 0 0//将所有盘进行挂载
$ sudo mount -a//查看正常挂载后的文件系统
$ sudo df -ah
/dev/mapper/ubt1404--vg-disk1 20G 44M 19G 1% /ldisk/disk1
/dev/mapper/ubt1404--vg-disk2 20G 44M 19G 1% /ldisk/disk2
...//如果data.dir 配置失败可以尝试手动创建dn数据目录。在每个挂载点下新建dn目录,并修改合适的目录权限
$ sudo mkdir /ldisk/disk1/dn
$ sudo chown hdfs.hadoop /ldisk/disk1/dn
安装CM(Server/Agent):
CDH5.10之前版本可能需要手动创建cloudera-scm用户(所有节点)
$ sudo useradd --system --home=/var/lib/cloudera-scm-server --no-create-home --shell=/bin/nologin --comment "Cloudera Manager" cloudera-scm
$ cat /etc/passwd
cloudera-scm:x:105:112:Cloudera Manager,,,:/var/lib/cloudera-scm-server:/bin/nologin
1.安装Cloudera Manager Server(主节点)
$ sudo apt-get install cloudera-manager-daemons
$ sudo apt-get install cloudera-manager-server
***在线安装过程较长,可将apt下载好的deb包(/var/cache/apt/archives目录下)copy出来,通过 dpkg -i –R <deb_dir> 进行离线安装。
完成安装后文件路径:
/usr/sbin/cmf-server
/usr/sbin/cmf-agent
初始化Cloudera Manager的数据库(手动)
//mark: configure clouder manager metadata to saved in the MySQL.
$ sudo /usr/share/cmf/schema/scm_prepare_database.sh mysql cmf -hlocalhost -uroot -pxxxx --scm-host localhost scm scm scm
***执行scm_prepare_database.sh 初始化数据库后不需要手动修改cm数据库配置文件。

修改cm数据库配置文件(手动)
$ sudo /etc/cloudera-scm-server/db.properties

2.启动CM服务(主节点)
$ sudo service cloudera-scm-server start
第一次启动服务时间较长,cmf数据库初始化,直到7180端口起来才启动完成:

3.安装Cloudera Manager Agent(所有节点)
//此步骤在cm添加节点时自动部署,这里可提前手动安装缩短部署时间。
$ sudo apt-get install cloudera-manager-daemons
$ sudo apt-get install cloudera-manager-agent
***在线安装过程较长,可将apt下载好的deb包(/var/cache/apt/archives目录下)copy出来,通过 dpkg -i –R <deb_dir> 进行离线安装。
修改Agent配置文件
$ sudo vi /etc/cloudera-scm-agent/config.ini
server_host= cdh01 //主节点的主机名
4.准备Parcels(离线部署CDH5)
CDH5 parcel最新版下载地址:
http://archive-primary.cloudera.com/cdh5/parcels/latest/
相关的parcel文件如下(这里为CDH 5.10.1 for ubuntu 14.04版本):
CDH-5.10.1-1.cdh5.10.1.p0.10-trusty.parcel
CDH-5.10.1-1.cdh5.10.1.p0.10-trusty.parcel.sha1//注意将CDH-5.x.x-x.xxx.xx.parcel.sha1,重命名为CDH-5.x.x-x.xxx.xx.parcel.sha,否则,系统会重新下载CDH-5.1.3-1.cdh5.1.3.p0.12-el6.parcel文件。
将下载的Parcel包放到主节点的/opt/cloudera/parcel-repo/目录中(parcel-repo需要手动创建):

通过CM部署Hadoop集群:
1.配置集群主机
Cloudera Manager 浏览器认管理账号:
User:admin
Password:admin

首次登陆进入集群安装向导:


2.Parcels部署前的准备

//这里不用再选择安装JDK

//选择传统模式安装,不启用单用户模式

//CDH5.10这里请直接选择以root 用户(CDH会自动为不同的服务建立不同的用户):

//这一步安装是为每个节点安装cloudera-manager-daemons 和 cloudera-manager-agent,前面已经手动安装了,所以很快完成:

//将CDH parcels分发到各个点等待安装:

//主机配置条件兼容性检查,满足所有条件后再开始下一步的安装:
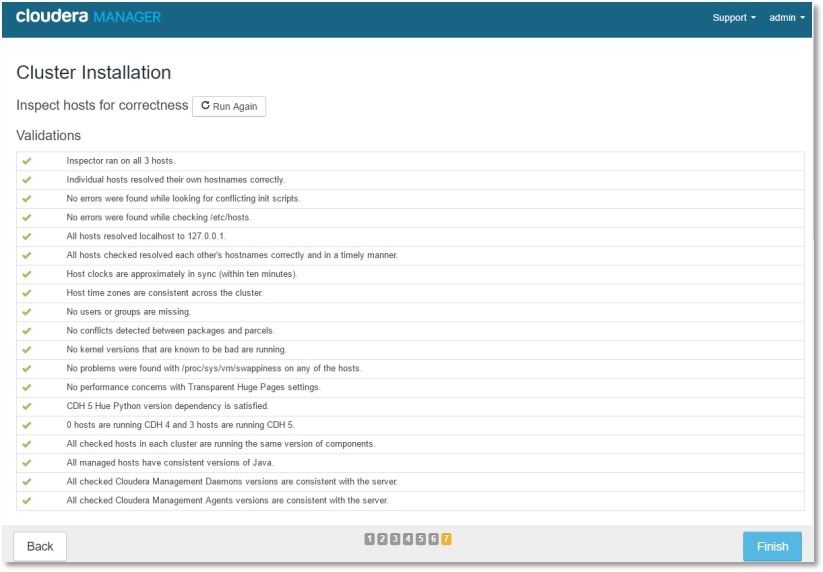
3.CDH集群安装
//选择Hadoop集群安装组件

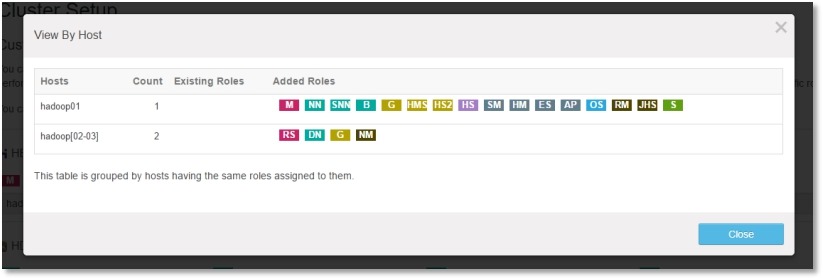
//将个组件/角色合理的分配到不同的主机上:

//管理节点承担了较多的角色,建议内存配大一些(角色后续也可以根据需要分配到其它节点):
//这里database主机名填 localhost 验证通过:

//预览所有配置信息,规划好DataNode和NameNode的数据存储路径(后续也可以进行调整):

//确认配置后,开始集群的安装:

//这个过程时间相对较长,遇到报错根据log的内容排查问题,然后在retry会继续进行,如果不小心关掉了这个页面可以在Running Commands 里找到First Run 这个任务继续:

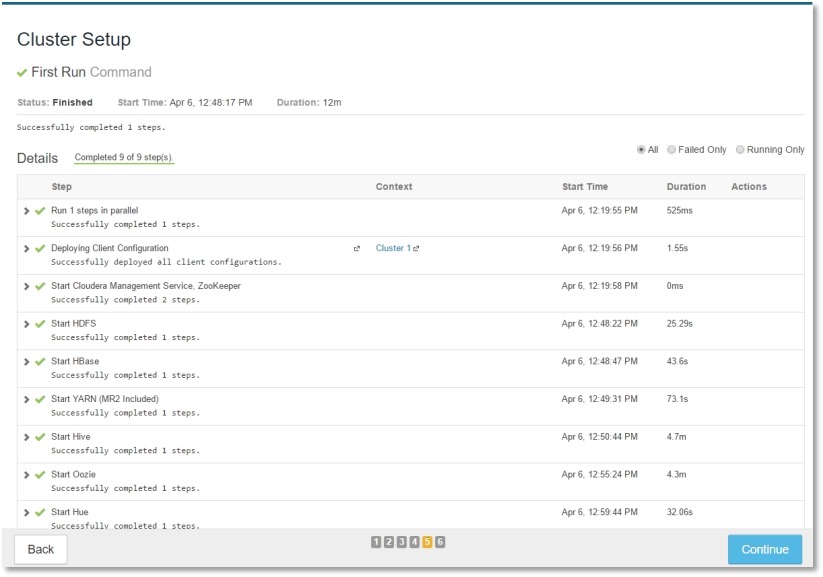
完成Hadoop集群的安装:

Hadoop集群配置相关
Hadoop集群计算测试
登陆到集群中任意节点,以hdfs用户执行测试任务(用Hadoop计算PI值,圆周率)
$ hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 10 10000


配置HDFS数据目录
在HDFS配置页面找到HDFS DataNode 存储目录(dfs.data.dir/dfs.datanode.data.dir)
前面已经为每个磁盘挂载到一个目录下,这里将这些目录都添加上,需要注意这里不能直接添加挂载点的目录,需要指向挂载点下的一个子目录,例如 /ldisk/disk1/dn

集群重新配置后,可以看到HDFS容量已经得到增加:

配置HDFS副本数
在HDFS配置页面,通过dfs.replication 筛选出副本数配置项目,默认为[3]:

新增服务到集群
选择集群,操作,添加服务





